The full tagset of 37 is too large to esimate all models reliably, so
we investigated using smaller tagsets. To find the optimal tagset
size we tested a progression of tagset sizes starting from 37 down to
2. We used a greedy algorithm finding the best tag combination at
each stage. We found that a tagset size of 23 (formed by collapsing
the sub-categories of the four major categories in the original) gave
the best results. The following results show the results comparing
the original, the 23 size set and sets of size 3 and 2. ![]() only distinguishes words from punctuation, and
only distinguishes words from punctuation, and ![]() distinguishes
content words, function words and punctuation. An ngram of length 6
was used throughout (see below).
distinguishes
content words, function words and punctuation. An ngram of length 6
was used throughout (see below).
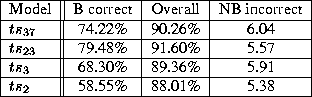
In general our experiments showed that the optimal tagset size is between 15 and 25. Our standard tagset of 23 could be reduced slightly with a small improvement by combining rare tags (e.g. fw, foreign word) into the major categories.